![[Artful Image]](powerseries/pstech1.jpg)
Along with Silicon Graphics' legendary graphics - an enhanced version of our fully interactive 3D graphics - the POWER Series includes the most powerful RISC-based multiprocessor architecture available today. Never before have such powerful analytical and graphics resources been integrated to serve technical applications.
Many applications that currently depend on supercomputers or other large computing systems can now run at comparable speeds on the POWER Series Graphics Supercomputing Workstations and Supercomputing Servers. The POWER Series' "immediate mode" 3D graphics and compute power open new possibilities in many applications, including computational fluid dynamics, molecular modeling, mathematical theory, computational chemistry, and medical imaging. The capabilities of the POWER Series also expand the performance of applications such as scientific visualization, creative graphics, mechanical design, and visual simulation.
![[Another Artful Image]](powerseries/pstech2.jpg)
The POWER Series Graphics Supercomputing Workstations rely on two distinct, yet highly interactive hardware subsystems: the GTX graphics subsystem and the POWERpath architecture computational subsystem. Because the multiple POWERpath architecture CPUs are not burdened with the graphics overhead, they devote their power exclusively to analytical tasks. And the dedicated graphics hardware ensures full-speed graphics rendering independent of CPU activity. Thus, the independent subsystems boost overall performance and promote maximum interaction between analysis and graphics, ensuring maximum resource utilization.
This approach contrasts with that of other graphics architectures, which require that one set of computational resources handle both analysis and graphics. Thus, neither analysis nor graphics receives the compute power desired, and the general-purpose computer bus is constantly burdened with massive amounts of pixel data.
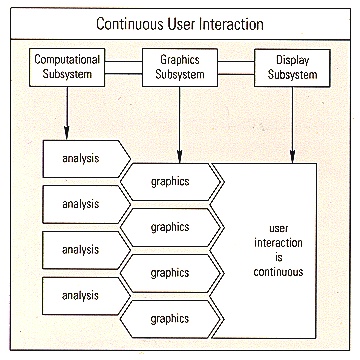
The POWERpath architecture avoids these problems by using the separate computational and graphics subsystems and by implementing efficient communications between the subsystems. Specifically, because the CPUs transfer data to the graphics subsystem only once, the POWERpath architecture buses carry relatively little graphics data of any kind and no pixel traffic.
A significant characteristic of the POWER Series systems is that they support parallel processing rather than vector computing in both the computational and graphics subsystems. This characteristic contrasts with the use of vector architectures in many other systems to perform a wide variety of tasks. However, only highly vectorizable code can take advantage of such systemsand few applications are highly vectorizable. Graphics tasks, in particular, rarely run efficiently on vector systems. The POWER Series' parallel approach ensures that any application can make efficient use of the available power.
POWER Series Choices
The POWER Series includes six models: Three POWER IRIS Graphics Supercomputing Workstation configurations include Silicon Graphics' industry-leading GTX graphics. And three POWER Station configurations can be used as Supercomputing Servers and general-purpose technical computers in a networked environment.
POWER IRIS Models
Users of any Silicon Graphics 4D superworkstation can upgrade to any of the POWER IRIS configurations, with the 4D/ GTX upgrade. The upgrade includes both the POWERpath parallel processing architecture and the GTX graphics subsystem.
POWER Station Models
The POWERpath Architecture
 To maximize the amount of compute power available from the industry's
most powerful RISC processors, the POWERpath architecture employs an
innovative structure containing specialized buses; multiple
processors; and a shared, hierarchical memory structure. The main
processors are the 16-MHz R2000 and the 25-MHz R3000 scalar units and
their associated R2010 and R3010 floating point units from MIPS
Computer Systems. These processors work with custom VLSI chips
developed by Silicon Graphics, including a specialized
error-correcting chip for the memory subsystem and custom controllers
for processor synchronization.
To maximize the amount of compute power available from the industry's
most powerful RISC processors, the POWERpath architecture employs an
innovative structure containing specialized buses; multiple
processors; and a shared, hierarchical memory structure. The main
processors are the 16-MHz R2000 and the 25-MHz R3000 scalar units and
their associated R2010 and R3010 floating point units from MIPS
Computer Systems. These processors work with custom VLSI chips
developed by Silicon Graphics, including a specialized
error-correcting chip for the memory subsystem and custom controllers
for processor synchronization.
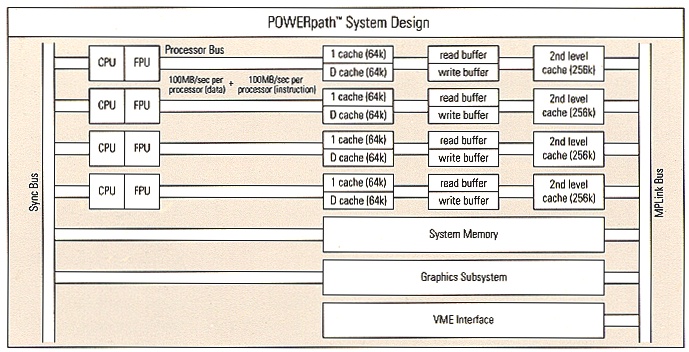
Among the POWERpath architecture's many innovations is a bus structure that helps make these Graphics Supercomputing Workstations modular, balanced, and expandable. The modularity derives from the use of specialized buses for specific functions, which minimizes bus contention and boosts overall bus bandwidth. The architecture is balanced because bus capacity has been carefully matched to the requirements of the hierarchical memory structure. And the system is expandable in that bus bandwidth increases as processors are added; thus the 2-processor system does not bear the cost of the extra bandwidth needed for the 4-processor version.
The POWERpath architecture is a tightly coupled, symmetrical, shared-memory multiprocessor. Each processor - along with its associated floating point unit - operates on its own Processor Bus. Each processor also works with its own caches and read/write buffers. For example, the 25-MHz systems include a 64-Kbyte first-level data cache, 256-Kbyte second-level data cache, read and write buffers, and 64-Kbyte instruction cache. All caches employ fast static RAMs.
![[Another Artful Image]](powerseries/pstech3.jpg)
Two other main buses furnish global access. The MPLink Bus connects each processor to main memory, the I/O system, and the graphics subsystem. This bus supports protocols for consistent data sharing and high-speed block data transfers. Finally, the Sync Bus coordinates the system's multiple processors to allow them to function as a tightly integrated unit.
The Processor Bus
As the local bus that serves individual processors, the Processor Bus includes both an address and data bus. They support sustained data transfers at 8 bytes per clock cycle. Thus, a 4-processor POWER Series system has a total processor-to-cache bandwidth of 800 Mbytes per second. This bandwidth can result in great performance benefits for the many large tasks that are as constrained by data bandwidth as by available compute cycles.
The Sync Bus
The Sync Bus allows applications to make efficient use of the POWERpath architecture's parallel processors, even at the level of individual loops. By providing 65,000 test-and-set variables, the Sync Bus supports very fine-grained locks for many purposes. Except for the 4,000 locks used by the operating system, these locks are available for use by user systems.
Because the Sync Bus can furnish synchronization operations with an overhead of only a few cycles, many programming and compiler techniques developed for vector processors also suit the POWERpath architecture parallel processor. For example, strip mining - breaking a long vector into multiple strips - can produce super-linear speed improvements. The Sync Bus also distributes interrupts among the processors and the I/O system.
Because the Sync Bus synchronizes the processors, the cache consistency protocol can support efficient data sharing between processors. If the cache consistency had to support synchronization as well as data sharing, the data sharing efficiency would have to be compromised. Separate buses therefore provide the opportunity to handle crucial functions with maximum efficiency.
The MPLink Bus
Using a pipelined, block-transfer approach, the MPLink Bus connects the processors, memory, I/O system, and the graphics subsystem. The MPLink Bus also supports the cache consistency protocol.
The MPLink Bus interfaces with the processors via read and write buffers asynchronously. This makes it possible for Silicon Graphics to increase the performance of the systems in the future by incorporating faster processors, without altering the rest of the POWERpath architecture.
IRIX Supports Resource Sharing
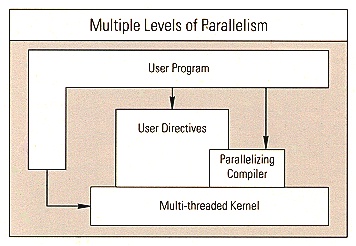
The IRIX operating system is tailored to take maximum advantage of the POWERpath architecture's parallel structure. IRIX is based on UNIX System V, and maintains full compatibility with that operating system, yet goes far beyond standard UNIX in utilizing fine-grained parallelism.
The primary concern in a parallel processing system is efficient resource sharing, especially in regard to data structure access. The IRIX kernel supports the POWERpath architecture's low-level resource-sharing model with a new programming paradigm. Although similar to threads or lightweight processes, the new paradigm entails little of the programming burden imposed by the older schemes.
IRIX is a fully parallel, symmetrical multiprocessing operating system, with no master/ slave assignments for any of the processors. Because each processor can execute kernel code, an executing process gains full use of its scheduled processor. Processors are self-scheduling and work from a single run queue maintained by the kernel.
In addition to the process-level parallelism provided by IRIX, there are two other models of parallelism. One model is parallelism at the procedure level. Programming tools provide the C, FORTRAN, Pascal, Ada and PL/I programmer with the ability to break up a single process at a functional level and run the parts on different processors. For performance tuning, IRIX profiling tools quickly give information about where code might benefit from parallelizing and evaluate the effectiveness of a parallelized version.
The other model of parallelism, available to FORTRAN programmers only, is loop level parallelism. Knowledgeable programmers can add compiler directives to their code which assign different loop iterations to different processors. Alternatively, the POWER FORTRAN Accelerator performs a data dependency analysis and automatically inserts these compiler directives into any FORTRAN program.
At a low level, more than 4,000 hardware-supported spinlocks provide access to single-bit flags, which indicate short-term ownership of a resource. Since the IRIX kernel is locked at such a fine level, multiple streams can execute in the kernel with very small chance of contention.
All shared data structures - such as inodes, buffers, or process table entries - are protected by some form of lock, which allows multiple processors to access the data structures in parallel without interference. Moreover, the POWERpath architecture's use and format of shared data structures minimizes the amount of spinlocking required. Lock and semaphore metering ensures that locking overhead is kept to minimal levels.
Graphics Subsystem
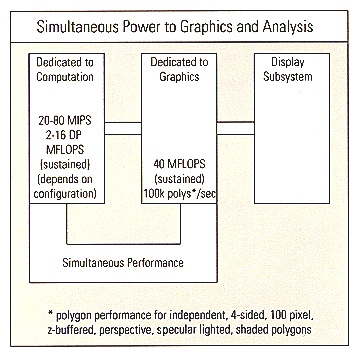
The POWER Series GTX graphics subsystem contains a pipeline of custom graphics processors along with specialized rendering processors. These 50 proprietary processors furnish hardware support for graphics characteristics such as multiple, colored, local, and infinite lights; flat and smooth shading; anti-aliased lines; backface polygon removal; six-axis clipping; depth cueing; and pan and zoom. The graphics pipeline handles object rotation, translation and scaling, perspective or orthographic viewing, and scaling to screen coordinates at high speed. In all, the GTX processors provide 40 MFLOPS of sustained performance dedicated exclusively to graphics processing.
The subsystem's frame buffer contributes the ability to display as many as 16.7 million colors. And a 24-bit Z-buffer permits fast hidden surface removal as well as overlays and underlays for picture enhancement or user interface functions.
The GTX subsystem accepts vertex data from the POWERpath architecture subsystem via DMA, which allows overlap between moving the data and setting up the next vertex. This highly efficient procedure is handled automatically by the Graphics Library and is transparent to users. In addition to previously available Graphics Library capabilities, the GTX provides both microcode and software support for the display of trimmed non-uniform rational B-spline (NURBS) surfaces.
The graphics resources of the POWER Series GTX render 100,000 Z-buffered, 4-sided, Gouraud shaded, Phong lighted, independent polygons per second. The GTXs pixel writing rate of 8 million pixels per second and vector rate of 400,000 vectors per second complement the analysis capability of the POWER Series Graphics Supercomputing Workstations.
The Technical Solution
In contrast to systems that provide either very high compute power or high-performance graphics, the POWER Series Graphics Supercomputing Workstations and Supercomputing Servers from Silicon Graphics deliver both. The POWER Series' dedicated computing and graphics hardware keep both functions running at full speed.
The combination of powerful analysis and graphics performance in one system allows you to interact with your applications graphically and continuously, rather than waiting to visualize data from an external computer running a batch-mode application.
See for yourself. For more information and a demonstration of the POWER Series Graphics Supercomputing Workstations and Supercomputing Servers, call or write the Silicon Graphics sales office closest to you.
Size and Weight:
UNIX is a registered trademark of AT&T.
Ethernet is a registered trademark of Xerox Corporation.
DecNet is a trademark of Digital Equipment Corp.
NFS is a trademark of Sun Microsystems.
Silicon Graphics, Silicon Graphics logo, POWER Series, POWERpath,
Graphics Library, POWER IRIS, POWER Station, 4Sight are trademarks
of Silicon Graphics.